- Published on
- Reading Time
10 min read
A Whole Day Playing with IPFS

This is pretty much a controversial decentralized web technologies research story but, before starting, there are a few things I'd like to ensure you all, my beloved readers, are aware of.
The first one is my original purpose during this first Mad Science Weekend: I wanted to do some research around a few of the main buzz words we have nowadays when it comes to decentralized web, focusing on the famous peer-to-peer protocol: IPFS, making simple examples (PoCs) so that we can evaluate if it is suitable for usage in one of the Beakyn’s applications in order to find a more efficient, cheap, and reliable way to serve our data.
Secondly, I have sort of a disclaimer: this post can, sometimes, sound more technical than it really is, so don't you feel afraid of any buzz word and ping me if you have any kind of questions or other feedback–as Juan usually says:
“Hey stupid! You could do this or that”.
Research Organization
The final result of this research is split in three different parts:
- Research Synthesis ↝ Guess what? The post you're reading right now 🙈.
- Sample Publishing Script ↝ This is a simple Node.js script which basically fetches our last
.pbffiles, encrypts them, and then publishes the data to IPFS. It also contains a few helper functions for encrypting/decrypting data which are built on top of Crypto and URSA. mad-science-weekendbranch ↝ I wanted to test all this stuff in a scenario that is a bit closer to the real world; so I ended up with a branch on one of our systems which fetches.pbf files from IPFS hashes instead of regular AWS endpoints.
Impressions
Here go a few of my general impressions when it comes to IPFS/IPNS and other related stuff that ended up being part of my studies–e.g. Data Encryption.
Overview
If you don't need anything like an IPFS 101, just skip all this section 😎.
In summary, it consists of a peer-to-peer protocol for distributed file systems. The simplest way to access the content in IPFS is by its public gateway, tough it’s possible to run a daemon locally or host gateway of your own.
After any kind of data, such as a file, is added to IPFS, it then becomes the so called objects. Each object has a hash which is generated based on its content and will be available through it.
For example:
# If a text file containing "hello worlds" is added to IPFS:
> echo "hello worlds" | ipfs add
# Then it will be available with the following hash:
added QmZ4tDuvesekSs4qM5ZBKpXiZGun7S2CYtEZRB3DYXkjGx
> ipfs cat QmZ4tDuvesekSs4qM5ZBKpXiZGun7S2CYtEZRB3DYXkjGx
ipfs
All objects contained in IPFS are immutable which means that if it’s necessary to add a new version of a file, a new object will be created, completely regardless of the previous one. Then a brand new hash is obtained–and the previous one will still to be available due to its immutable nature.
If the text from the previous example gets changed to IPFS, we’re going to have a new hash representing it:
QmbXBAKDgbhE8HkGuEF4FuQQJej2mxqXtYSMsBPuJDqgjq
This happens due to the concept of Content Addressable Storage which is strongly present in IPFS. That is, the data in IPFS is addressed by one hash generated from its content, ensuring:
- More integrity, regardless of where or who offers the content.
- That the links are permanent; always pointing to same object.
Latency
tl;dr: Negative.
Although the concept of content-addressing brings a bunch of benefits, initially it’d become unsuitable for cases where it’s necessary to constantly get the last version of something, since it’d need to get the hash of last version of the object in another channel.
To solve this problem another protocol, called IPNS, was developed. With the peerId, the hash of the user's public key, it then became possible to create a redirect to a specific object. So, for didactic purposes, you may want to understand IPNS as a small amount of mutability to the permanent immutability that is IPFS, since it allows you to store a reference to a hash and update what that reference points to by simply executing a publish command.
Intermission: It’s important to emphasize this due to the fact that the content on the platform I'm using on this PoC is synchronized with data from other platform of ours every day at a set time. This means that every day a bot on Amazon Elastic Compute Cloud (AWS EC2) reads the data from one our MongoDB instances and then generates a few
.pbffiles which are then served via the Amazon Simple Storage Service (AWS S3).
Resilience
tl;dr: Positive.
Something at least interesting when it comes to the IPNS usage is the name availability time. Whenever the bot running on the AWS EC2 instance adds a new object to IPFS and creates a redirect of its IPNS hash to the new object, it can then shutdown the daemon in its computer. The IPFS node–which includes the public gateway one–, will keep holding the IPNS address using a cache system.
In other words, we do know that someone needs to resolve the IPNS address. We also know that this guy, in general, is the owner of IPFS hash that says "Hey, my IPNS hash points to that object over there". However, the IPFS network also caches the resolution of that name, so then if the node is down, that IPNS hash is still resolvable–which, by the way, has a lifetime of up to 36 hours.
For our context, since there is always an active instance which publishes the data in IPFS, we generally don’t have to worry about the expiration of IPNS resolution. Since the data changes every 24h, and the lifetime is 36h, even if we faced downtime, the resolution would still be available.
This may represent a gain in resilience since none of the experienced service disruptions would affect the availability of the .pbf data.
Sensitive Data
tl;dr: DEFINITELY Needs more research.
Due to the very sensitive nature of the data our .pbfs hold, it turns out to be necessary to find a way of ensuring that this data is only accessible to our trusted clients.
Since there seem to be many alternatives–and given the time constraints–, it was hard for me to choose between one of them.
When it comes to IPFS itself, SWARM filters at first sight seemed to be a good alternative but it was still unclear to me how experimental they were. Also, I thought about private networks–which enforce connection to only peers who have a shared secret key–but it is documented as still experimental, too.
Other alternatives–which are actually kind of alternatives to IPFS itself–are the ones designed focused on private usage–e.g. Peergos and Camlistore.
For this PoC, the chosen approach was encrypting files before adding them to IPFS–yeah, I know at first sight it seems to be a naive choice, but the IPFS creator, Juan Benet, has already mentioned he used this strategy for his personal files.
Although we use a few good optimization techniques–e.g. this lightweight Protobuf implementation and the Brotli compression algorithm–the amount of data we have to encrypt–about 8 .pbf files which hold geodata from thousands of Points Of Interest (POIs)–is still considered large data depending on the size of the RSA generated key due to this issue on URSA.
As it can be seen in the figure below, in an experiment during this PoC, a 2^13 bytes-sized RSA key wasn't able to encrypt even one of our 8 geodata chunks using URSA–which is, by the way, one of the most used OpenSSL bindings for Node.js.
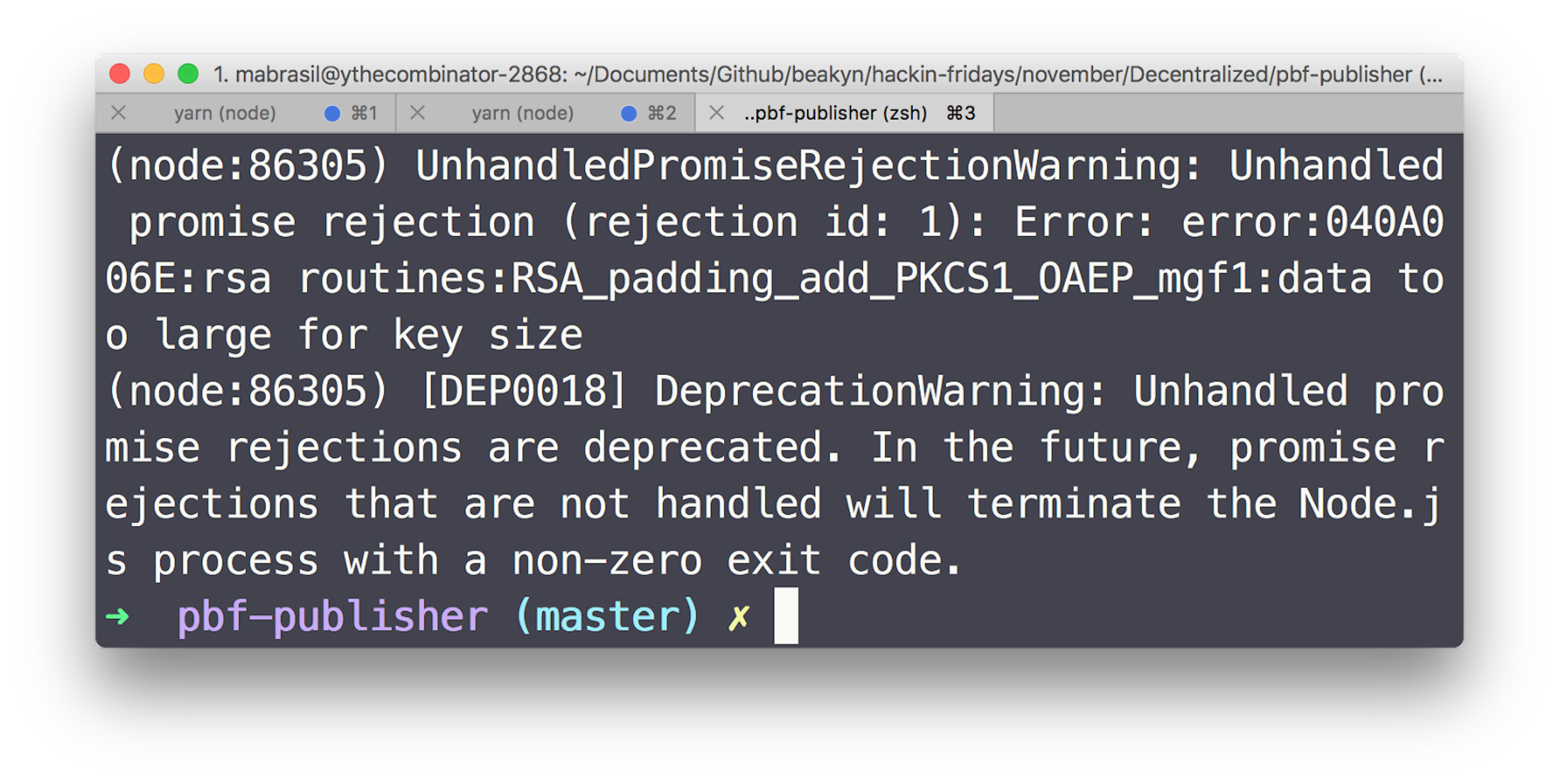
The used RSA key was generated using genrsa from OpenSSL 0.9.8 running on darwin64-x86_64-llvm inside a MacBook Pro (8 GB 1867 MHz DDR3 | 2,7 GHz Intel Core i5).
Given those limitations, I came up with symmetric cipher based approach, using a simple AES 256-based encryption that comes built-in with Node.js.
At The End of The Day…
… I noticed I had a lot of fun 🔝🌈🌟🎇🎆.
I kinda see that there are probably many good cases here at Beakyn where IPFS could be a nice player–even this blog could be built on top of it–but, as of now, and given the fact that this was just a short weekend research–so don't look at me as the decentralized web guru–, I think that, for the specific case described during the post, everything considered, it's not suitable, mainly because of the extra layers of concerns it seemed to add when it comes to latency and sensitive data security.
Last but not least, a very special thanks goes to both Bruno and Marcus–two friends of mine–for being so attentive to all my doubts and always being available for long conversations involving decentralized web stuff.
Things I Would Like to Have Studied More
These are a few subjects/technologies I’d like to have read more about–and which each would result in a different Mad Science Weekend:
IPNS ↝ I do believe that better understanding naming resolution under-the-hood would help me being able to collaborate on the latency issue solving, or at least understand its roots.
Peergos ↝ As a peer-to-peer encrypted filesystem–built on the top of IPFS–, at first sight, it seemed to me like a solution closer to what we’re looking for given its private sharing design goal.
Camlistore ↝ Again, given my superficial impressions, it seemed to me like a solution closer to what we’re looking for.
Y.js ↝ Offline-first p2p shared editing would be something amazing to have on the other systems of ours–e.g. something that evolves map data creation.
OrbitDB ↝ Given its key-Value store nature, it could be a good MongoDB replacement in a scenario where we migrate our stack to a decentralized one.
References & Further Reading
Amazon Web Services Reports. (2017). Summary of the Amazon S3 Service Disruption in the Northern Virginia (US-EAST-1) Region.
Benet, J. (2015). IPFS — Content Addressed, Versioned, P2P File System.
Dave Longley (2013). [Failed to encrypt buffer with length 256 with 2048 bit RSA · Issue #14]( Failed to encrypt buffer with length 256 with 2048 bit RSA · Issue #14).
Hartmann, C. (2014). [Encrypt and decrypt content with Nodejs](Encrypt and decrypt content with Nodejs.).
IPFS (2016). Questions after first learning about IPFS · Issue #154.
IPFS (2016). Is it possible to store private objects in ipfs without encrypting them? · Issue #181.
IPFS (2016). Private/personal use of ipfs? · Issue #4.
IPFS (2016). Keystore/encryption/ipfs usecase for a file-sharing application · Issue #3866.
Macabeus, B. (2017). IPFS and IPNS protocols as way for controller of botnet: a proof of concept.
Mutunhire, T. (2017). Writing to Files in Node.js.
OrbitDB (2017). orbitdb/orbit.
Reed, J. (2017). Privacy and anonymity in IPFS/IPNS.
The Golem Project. (2016). The Golem Project Crowdfunding Whitepaper.
Zumwalt, M., Johnson, J., Benet, J., Gierth, L. and Fisher, L. (2017). The Decentralized Web Primer.
Thanks for reading!
Share this post with your friends: